Getting started testing
This talk
- Why test?
- How to write tests?
- How to run your tests?
- What kinds of tests to write?
- Testing workflows.
Me
- Writing Python since 2002.
- Professionally since 2007.
- Writing a lot of tests since 2009.
- Mostly web development.
- OSS: pip, virtualenv, Django
A very brief story about me, Python, and testing...
I like to write tests. Even this slide deck has tests!
I mostly do web development, but I've tried to keep this talk general.
I didn't create these things, but I've done a lot of work on them.
Let's make a thing!
A GitHub recommendation engine!
Find the projects you ought to know about...
It's been done already. Oh well.
gitrecs.py
def similarity(watched1, watched2): """ Return similarity score for two users. Users represented as iterables of watched repo names. Score is Jaccard index (intersection / union). """ intersection = 0 for repo in watched1: if repo in watched2: intersection += 1 union = len(watched1) + len(watched2) - intersection return intersection / union
Similarity score, 0 to 1.
Jaccard index: intersection over union.
Terrible implementation: buggy and slow. Software!
Now of course we want to make sure it works!
It works!
>>> similarity(['a', 'b'], ['b', 'c', 'd']) 0.25 >>> similarity(['a', 'b', 'c'], ['b', 'c', 'd']) 0.5 >>> similarity(['a', 'b', 'c'], ['d']) 0.0
So far, so good!
But here's a bug...
Uh oh
>>> similarity(['a', 'a', 'b'], ['b']) 0.3333333333333333
Jaccard index is a set metric, and our bad implementation doesn't handle duplicates correctly. Should be 1/2, got 1/3.
Fortunately, Python's got an excellent built-in set data structure, so let's rewrite to use that instead and fix this bug!
Now with more set
def similarity(watched1, watched2): """ Return similarity score for two users. Users represented as iterable of watched repo names. Score is Jaccard index (intersection / union). """ watched1, watched2 = set(watched1), set(watched2) intersection = watched1.intersection(watched2) union = watched1.union(watched2) return len(intersection) / len(union)
Fixed!
>>> similarity(['a', 'a', 'b'], ['b']) 0.5
Great, works!
But we totally rewrote it, better make sure we didn't break anything...
Did we break anything?
>>> similarity({'a', 'b'}, {'b', 'c', 'd'}) 0.25 >>> similarity({'a', 'b', 'c'}, {'b', 'c', 'd'}) 0.5 >>> similarity({'a', 'b', 'c'}, {'d'}) 0.0
All good!
This gets old.
- Repetitive and boring.
- Not easily reproducible.
- Error-prone.
- The bigger the system, the worse this gets. (14th survey page.)
- What happens with boring tasks? I skip them! Now I'll ship broken code!
- If it breaks for you, hard to tell another developer how to see the breakage.
- Did I calculate all those results right? Will I do it right next time?
We're software developers!
- Automating boring things is what we do.
We know how to handle boring repetitive tasks, we write software to automate them!
test_gitrecs.py
from gitrecs import similarity assert similarity({'a', 'b'}, {'b', 'c', 'd'}) == 0.25 assert similarity(['a', 'a'], ['a', 'b']) == 0.5
Better! Easily repeatable tests.
Hmm, another bug.
A bug!
from gitrecs import similarity assert similarity({}, {}) == 0.0 assert similarity({'a', 'b'}, {'b', 'c', 'd'}) == 0.25 assert similarity(['a', 'a'], ['a', 'b']) == 0.5
Traceback (most recent call last):
File "test_gitrecs.py", line 3, in <module>
assert similarity({}, {}) == 0.0
File "/home/carljm/gitrecs.py", line 14, in similarity
return len(intersection) / len(union)
ZeroDivisionError: division by zeroWe can fix the bug, but we have a problem with our tests: because the first one failed, none of the others ran.
It'd be better if every test ran every time, pass or fail, so we could get a more complete picture of what's broken and what isn't.
def test_empty(): assert similarity({}, {}) == 0.0 def test_sets(): assert similarity({'a', 'b'}, {'b', 'c', 'd'}) == 0.25 def test_list_with_dupes(): assert similarity(['a', 'a'], ['a', 'b']) == 0.5 if __name__ == '__main__': for func in test_empty, test_quarter, test_half: try: func() except Exception as e: print("{} FAILED: {}".format(func.__name__, e)) else: print("{} passed.".format(func.__name__))
Some code to run each test, catch any exceptions, and report whether the test passed or failed.
Fortunately, we don't have to do this ourselves; there are test runners to do this for us!
test_empty FAILED: division by zero test_sets passed. test_list_with_dupes passed.
pip install pytest
from gitrecs import similarity def test_empty(): assert similarity({}, {}) == 0.0 def test_sets(): assert similarity({'a', 'b'}, {'b', 'c', 'd'}) == 0.25 def test_list_with_dupes(): assert similarity(['a', 'a'], ['a', 'b']) == 0.5
One of these runners is pytest; we can install it and cut our test file down to just the tests themselves, no test-running boilerplate at all.
$ py.test
=================== test session starts ===================
platform linux -- Python 3.3.0 -- pytest-2.3.4
collected 3 items
test_gitrecs.py F..
======================== FAILURES =========================
_______________________ test_empty ________________________
def test_empty():
> assert similarity({}, {}) == 0.0
test_gitrecs.py:4:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
def similarity(watched1, watched2):
intersection = watched1.intersection(watched2)
union = watched1.union(watched2)
> return len(intersection) / len(union)
E ZeroDivisionError: division by zero
gitrecs.py:14: ZeroDivisionError
=========== 1 failed, 2 passed in 0.02 seconds ============Run py.test - it automatically finds our tests (because they are in a file whose name begins with "test", and each test function's name begins with "test") and runs them, with isolation so that even if one fails, they all run. (Can also run just one test file, or directory.)
It shows us the test file it found, shows a dot for each passed test and an F for each failed one. And we get some nice helpful debugging output around the failure too.
Now let's fix that bug.
def similarity(watched1, watched2): """ Return similarity score for two users. Users represented as iterable of watched repos. Score is Jaccard index (intersection / union). """ watched1, watched2 = set(watched1), set(watched2) intersection = watched1.intersection(watched2) union = watched1.union(watched2) if not union: return 0.0 return len(intersection) / len(union)
Tests pass! Ship it!
$ py.test =================== test session starts =================== platform linux -- Python 3.3.0 -- pytest-2.3.4 collected 3 items test_gitrecs.py ... ================ 3 passed in 0.02 seconds =================
Not only can we ship this code with some confidence that it works now, but also some confidence that if we change the implementation in the future and reintroduce any of these bugs, we'll catch it as soon as we run the tests.
Test runners
A brief synopsis and digression
- We saw py.test in action: pip install pytest; py.test
- Nose is similar: pip install nose; nosetests
- Both can run simple function tests with asserts.
- unittest is in the standard library, similar to "xUnit" test frameworks in various languages. Tests require a bit more boilerplate. python -m unittest discover
- Others: twisted.trial, zope.testrunner
If all these choices are overwhelming, don't worry about it. They're all fine, just pick one and run with it.
A unittest test
from unittest import TestCase from gitrecs import similarity class TestSimilarity(TestCase): def test_empty(self): score = similarity({}, {}) self.assertEqual(score, 0.0) def test_sets(self): score = similarity({'a'}, {'a', 'b'}) self.assertEqual(score, 0.5) def test_list_with_dupes(self): score = similarity(['a', 'a'], ['a', 'b']) self.assertEqual(score, 0.5)
Note the use of methods on self (assertEqual and friends) rather than simple asserts.
Why write tests?
- Tests tell you when your code is broken.
- Tests help later developers understand your code.
- Tests improve the design of your code.
- ... as we just saw. "More fun to write tests on weekdays than fix bugs on weekends." This is the primary reason most people write tests, and it's a plenty good one.
- A test is a form of documentation saying "this is what's important about this code." In a well-tested codebase, reading the tests along with the code they are testing is a great way to understand what that code is supposed to be doing.
- ...if you listen to them. How? Let's look at an example.
The first draft
class GithubUser: def get_watched_repos(self): """Return this user's set of watched repos.""" # ... GitHub API querying happens here ... def similarity(user1, user2): """Return similarity score for given users.""" watched1 = user1.get_watched_repos() watched2 = user2.get_watched_repos() # ... same Jaccard index code ...
You may have been thinking, of course tests are easy to write when you're testing nice simple functions like that similarity function.
Here's a secret: that wasn't the first version of similarity that I wrote. The first version looked more like this.
Imagine writing tests for this similarity function.
Harder to test
class FakeGithubUser: def __init__(self, watched): self.watched = watched def get_watched_repos(self): return self.watched def test_empty(): assert similarity( FakeGithubUser({}), FakeGithubUser({}) ) == 0.5 def test_sets(): assert similarity( FakeGithubUser({'a'}), FakeGithubUser({'a', 'b'}) ) == 0.5
We take advantage of duck-typing and create a fake replacement for GithubUser that doesn't go out and query the GitHub API, it just returns whatever we tell it to.
This is a fine testing technique when testing code that has a collaborator that is critical for its purpose. But when you have to do this, it should cause you to ask yourself if it's essential to what you want to test, or if the design of your code is making testing harder than it should be.
In this case, the collaborator is an avoidable distraction. What we really want to test is the similarity calculation; GithubUser is irrelevant. We can extract a similarity function that operates just on sets of repos so it doesn't need to know anything about the GithubUser class, and then our tests become much simpler.
Testable is maintainable
- Code maintenance == managing change.
- The less a function knows about the world, the more robust it is against changes in the world ("principle of least knowledge").
- The less a function knows about the world, the less of the world you have to set up in order to test it.
Function (or class, or module - whatever the system under test)
In this case, similarity is harder to test if it knows about GithubUser, because we have to set up a GithubUser (or a fake one) to feed to it for every test. And it's also more fragile, because if the name of the get_watched_repos method changes, it will break.
It knows more than it needs to know to do its job! By narrowing its vision of the world, we make it both easier to test and easier to maintain.
Unit tests
- Test one "unit" of code (function or method).
- Isolated (maybe not 100%).
- Small & fast!
- Focused: informative failures.
- Require more refactoring with code changes.
Integration tests
- Test that components talk to each other correctly.
- Slower; exercise more code.
- "Black box" end-to-end tests also called "system tests", "functional tests", "acceptance tests."
Unit.
- These are the tests we've been looking at.
- Unless collaborators are simple, replace with fakes.
- Don't exercise very much code.
Integration.
- Can be at various levels: testing integration of two different methods/classes, up to end-to-end tests of the entire system.
- Exercise more code; may also exercise external systems (e.g. database) that slow tests down.
Workflows for testing
Making testing a habit instead of a chore.
- Test first or test last?
- Test-first is more fun!
Too much religion around this question. Tests will help you no matter when you write them.
First you formulate clearly what you want your code to do, then you get to write code and get the satisfaction of seeing the test pass. Psychology of test-last is all wrong: first you get it working, then writing tests feels like a chore.
A feature-adding workflow
- Write a system test describing the working feature.
- Start implementation from the outside in.
- Programming by wish. "I wish I had a function that..." and stub it.
- For each stubbed function, write unit tests describing how it should actually work and complete the implementation to make those tests pass.
Programming by wish
def recommend_repos_for(username): my_watched = get_watched_repos(username) ... def get_watched_repos(username): # stub return {'pypa/pip', 'pypa/virtualenv'}
The "spike" workflow
When you need to write a bunch of exploratory code to figure out the problem space.
- Strict TDD says delete your spikes and rewrite them test-first.
- Try it; difference in second version can be illuminating!
- ...but I usually don't.
To write tests, you have to have some idea of the shape of the code you need to write. Sometimes for an unfamiliar problem space you have to write the code first to learn about what kind of shape it needs.
A bug-fixing workflow
- Write a test that fails because of the bug (a regression test).
- Focus the test (don't exercise more code than needed to highlight the bug).
- Fix the code so the test passes.
- Ship it!
Always, always step one. This is often part of finding and understanding the bug. If you haven't written a failing test, you don't have a bug identified yet.
A retrofitting workflow
- You have a codebase without tests. It probably isn't structured for testability.
- Start with system tests verifying the features you care most about.
- Even if you stop there, you still win!
- The integration tests give you confidence to refactor the code as you add unit tests.
- Use code coverage as a rough progress-tracking metric.
definition of legacy code: code without tests.
Measuring code coverage
- pip install coverage
- coverage run --branch `which py.test`
- coverage html
--branch: record not only which lines were and weren't executed, but also whether all branches of a conditional were taken.
coverage run is the most flexible way to run coverage (can run any python script); there are also plugins for py.test and nose that give it more integration with the test runner.
coverage html generates an HTML report.
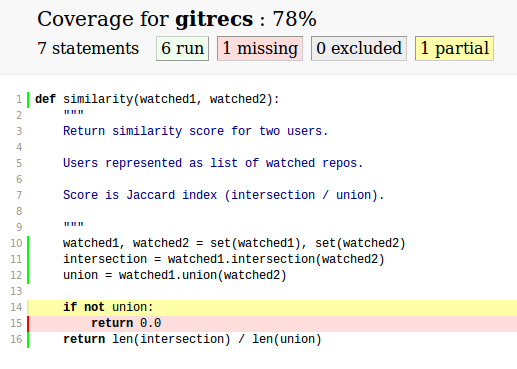
100% coverage only tells you that every line of code in your program can run without error. That's a good minimum baseline; it doesn't tell you whether those lines of code are actually doing the right thing! It is a useful way to make sure that you have at least one test checking every case that is handled by your code (including error cases).
See also:
- tox: test your library across multiple Python versions and configurations.
- mock: easily create fakes for testing (and monkeypatch them into place, if needed).
- WebTest: request/response testing for WSGI web apps.
- Selenium: browser automation (system tests for web apps).
Didn't have time to cover everything in depth, but here are a few more testing tools you should check out:
- If you're releasing a Python library that other devs will use, you probably want it to support at least two or three different versions of Python, plus possibly different versions of dependencies as well. This can quickly grow to a matrix of a size that's very hard to manage manually. Tox makes it easy to run your tests across this whole matrix.
- If you're writing a web app, a lot of your integration tests will be "send a request, check the response" - WebTest is a great tool for these tests.
Coding with tests...
- Is fun and satisfying!
- Reduces repetitive manual testing.
- Replaces fear with confidence.
- Results in better code.
- Worth the effort!
- Nothing like the satisfaction of seeing those rows of dots when all your tests are passing.
It's not easy: test code is real code and requires discipline, engineering, and investment to make it correct and maintainable. But it's worth it!